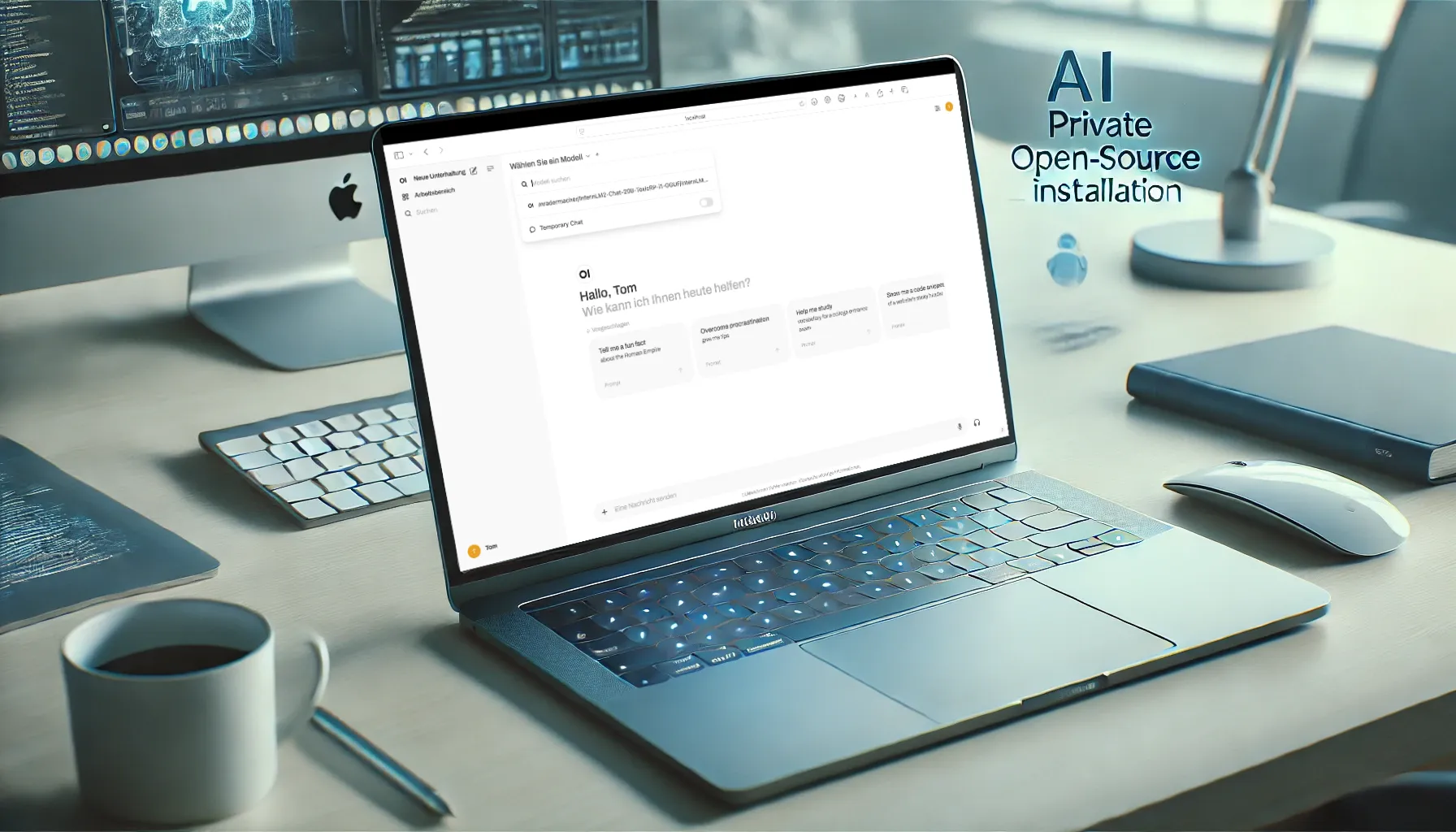
Du willst Large Language Models (LLMs) lokal auf deinem eigenen Mac testen — unabhängig von Cloud-Diensten, ohne Datenweitergabe? Auf Macs mit Apple Silicon (M1/M2/M3) gibt es dabei eine wichtige Herausforderung: Docker kann nicht auf die Apple Silicon GPU zugreifen. Die Lösung: OpenWebUI in Kombination mit LM Studio.
Das Problem mit Docker auf Apple Silicon
Die meisten Open-Source-LLMs werden über Tools wie Ollama oder OpenWebUI im Docker-Container verwendet. Aber Docker kann auf Macs die Metal GPU-Schnittstelle (Apple's GPU-API) nicht nutzen. Die Folge: LLMs laufen langsam auf der CPU statt auf der GPU.
Die Lösung: OpenWebUI als lokaler GUI-Server, verbunden mit LM Studio als Backend — das volle Metal GPU-Beschleunigung bietet.
Was ist OpenWebUI?
OpenWebUI ist ein lokal laufender GUI-Server, der wie ChatGPT funktioniert. Du kannst damit LLMs lokal hosten, ohne Cloud-Dienste — datenschutzkonform und offline-fähig.
Was ist LM Studio?
LM Studio ist eine Software, die speziell für die effiziente Nutzung von LLMs auf PCs und Macs mit Apple Silicon entwickelt wurde. Der entscheidende Vorteil: vollständige Unterstützung der Metal API — die GPU-Kerne des M-Chips werden voll genutzt.
Außerdem kannst du mit LM Studio alle Open-Source-LLMs von Hugging Face direkt herunterladen und zahlreiche Konfigurationsoptionen nutzen — im Gegensatz zu Ollama, das eher als Blackbox im Hintergrund arbeitet.
Voraussetzungen
- Mac mit Apple Silicon (M1, M2, M3)
- Mindestens 16 GB RAM (32 GB empfohlen für größere Modelle)
- macOS 14.0 oder neuer
- Ausreichend Festplattenspeicher (Modelle: 4–40 GB je nach Größe)
- Python 3.11 (wichtig: nicht 3.12 oder neuer)
Schritt 1: LM Studio installieren
- Lade LM Studio von lmstudio.ai herunter
- Installiere die App und starte sie
- Aktiviere unter Einstellungen → GPU die Metal-Beschleunigung
- Starte den lokalen Server unter Local Server auf Port
1234
Schritt 2: LLM suchen und laden
In LM Studio:
- Gehe zum Discover-Tab
- Suche z.B. nach
Mistral 7B InstructoderLLaMA 3.1 8B - Lade das Modell herunter (GGUF-Format, quantisiert für Apple Silicon)
- Lade das Modell in den Speicher und starte den lokalen API-Server
Schritt 3: OpenWebUI ohne Docker installieren
OpenWebUI kann auch ohne Docker in einer virtuellen Python-Umgebung installiert werden. Wichtig: Python 3.11 verwenden.
# Python 3.11 installieren (z.B. via pyenv)
pyenv install 3.11.9
pyenv local 3.11.9
# Virtuelle Umgebung erstellen
python -m venv openwebui-venv
source openwebui-venv/bin/activate
# OpenWebUI installieren
pip install open-webui
# Starten
WEBUI_AUTH=False open-webui serve --port 8080
Schritt 4: OpenWebUI mit LM Studio verbinden
- Öffne OpenWebUI unter
http://localhost:8080 - Gehe zu Admin → Einstellungen → Verbindungen
- Füge eine neue OpenAI-kompatible API hinzu:
- URL:
http://localhost:1234/v1 - API-Key:
lm-studio(beliebig)
- URL:
- Speichern — das Modell erscheint jetzt in der Modellauswahl
Ergebnis
Du hast jetzt einen vollständig privaten, lokal laufenden KI-Assistenten:
- Volle GPU-Beschleunigung via Apple Metal
- Keine Datenweitergabe an Dritte
- Funktioniert offline
- Unterstützt alle Open-Source-Modelle von Hugging Face
Empfohlene Modelle für den Anfang
| Modell | Größe | RAM | Qualität |
|---|---|---|---|
| Mistral 7B Instruct | ~4 GB | 8 GB | Gut für schnelle Aufgaben |
| LLaMA 3.1 8B | ~5 GB | 16 GB | Ausgezeichnet allgemein |
| Mistral Large | ~13 GB | 32 GB | Sehr gut, nah an GPT-4 |
Fazit
Mit dieser Setup-Variante holst du das Maximum aus deinem Apple Silicon Mac heraus. Die Kombination aus LM Studio und OpenWebUI ist in meiner Erfahrung die beste Option für Mac-Nutzer — effizienter als Docker-basierte Ansätze und voller Datenkontrolle.
